This file is both a HTML file and a literate Haskell program. If you rename it to .lhs you can compile it with GHC 6.6. This is a functional, if limited, JPEG decoder. It only decodes grayscale, 8-bit images and is overly sensitive to the options used.
I thought that people might like to learn a little about the JPEG standard. Frankly, you can just skip all the code if you don't understand Haskell.
A JPEG bitstream consists of several segments. Every byte in the file belongs to a segment and each segment follows a common format:
| u8 | 0xff |
| u8 | 0x01 .. 0xfe (segment type) |
| u16 be | header length (often included, but not always) |
After header length bytes may come an encoded stream of bytes. If the encoded stream of bytes contains an 0xff, a 0x00 is stuffed in afterwards to make sure that the 0xff isn't confused with the start of the next header.
I'm going to put in the first chunk of code now, so I have to get the module stuff out of the way. You can ignore this; these are all standard modules except for BitSyntax which is a helper module for parsing binary formats.
> import Maybe (fromJust) > import BitSyntax > import qualified Data.ByteString as BS > import System.IO (openFile, IOMode(..), hPutStr, hClose) > import Data.Bits > import Data.List (mapAccumL) > import Data.Word > import Control.Monad.Writer > import qualified Data.Map as Map
Now, here's the code which takes a JPEG file and returns a list of segments. It searches for the segment start marker and returns a list of segment types and the body of that segment. It's a little loose because it doesn't skip the segment header for those segments which have a length. Thus it's possible that it will find a marker in the headers. However, it suffices for our needs.
> jpegSegments :: BS.ByteString -> [(Word8, BS.ByteString)] > jpegSegments jpegdata = > if marker == 0xd9 > then [(marker, BS.empty)] > else (marker, bytes) : jpegSegments rest > where > marker = jpegdata `BS.index` 1 > indexes = BS.findSubstrings ff jpegdata > ff = BS.pack [0xff] > nextmarker = head $ tail $ filter (isMarkerAt jpegdata) indexes > isMarkerAt jpegdata i = nextbyte /= 00 && nextbyte /= 0xff > where nextbyte = jpegdata `BS.index` (i + 1) > bytes = BS.drop 2 $ BS.take nextmarker jpegdata > rest = BS.drop nextmarker jpegdata
At this point I'll introduce our test image:

Running jpegSegments on this file gives the following segments
| Type of segment | Length of segment |
|---|---|
| Start of image | 0 |
| APP0 | 16 |
| Quantisation table | 67 |
| Start of frame: baseline DCT | 11 |
| Huffman table | 28 |
| Huffman table | 63 |
| Start of scan | 49363 |
| End of image | 0 |
The APP0 segment marks this file as a JFIF/JPEG. JFIF defines some extra fields (like the image resolution and an optional thumbnail) and you can find out more about it here. Nearly all JPEGs found in the wild will be JFIF files.
The outline of the JPEG file is that it contains one frame (image) and that frame can one of more scans. Scans can give progressively more detail, or can be different axis of the colour space etc. For this example we have only one scan and only one axis of color space (luminance, because it's grayscale).
The quantisation and Huffman tables are needed for decoding the image so the first thing we do is parse and store the information in them. We'll be storing the information in a structure:
> data JpegState = JpegState { jsHuffTables :: Map.Map (Integer, Integer) Tree,
> jsQuantTable :: Map.Map Integer [Integer],
> jsWidth :: Int, jsHeight :: Int,
> jsACTable :: Int, jsDCTable :: Int, jsData :: BS.ByteString } deriving (Show)
There can be many Huffman and quantisation tables defined and different scans might use different tables. So we store a map of tables, although we only expect one.
First we parse the quantisation table (the segment is called DQT in the JPEG spec and you'll see these triplet names popping up now and then). Don't worry about what a quantisation table is quite yet, we'll get to that later, it's basically just an array of 64 values.The quantisation table segment looks like:
| u8 | 0xff |
| u8 | 0xdb (type of segment) |
| u16 be | length of segment |
| 4-bits | precision in bits |
| 4-bits | table id |
| 64 elements of u8 or u16 | quantisation values in zigzag order |
The last three rows are repeated for the length of the segment. Here's the parsing code
> parseDQT dqt = > parseTable $ BS.drop 2 dqt where > parseTable bytes = > if BS.length remainingbytes == 0 > then [(id, values)] > else (id, values) : parseTable remainingbytes > where > Just ([0, id], rest) = $(bitSyn [PackedBits [4, 4], Rest]) bytes > (valuesbytes, remainingbytes) = BS.splitAt 64 rest > values = map fromIntegral $ BS.unpack valuesbytes >
I'm going to assume that you know what Huffman coding is, if not you can read up on it. JPEG defines a mode for both Huffman and arithmetic coding but, due to patent issues, only Huffman is ever seen in the wild. Arithmetic coding is slower, but gets about 10% better compression for JPEG files.
The Huffman trees in JPEG are never deeper than 16 elements and they are communicated with two lists. The first is 16 elements long and gives the number of values at each depth in the tree. (So the first element gives the number of values which are only one step from the root of the tree, the second the number which are two steps etc.). The second list is a list of elements, in order of depth.
The JPEG standard gives a very complex definition of how to construct the Huffman trees (which appears to be a case of premature-optimisation). The actual algorithm is this:
Here's our tree structure:
> data Tree = Empty | Full Int | Tree Bool Tree Tree deriving (Show, Eq) > data Branch = TLeft | TRight deriving (Show, Eq)
Each node in the tree is either Empty, Full (a leaf node, with in Int element) or a tree with a fullness-flag, and left+right children. The fullness flag for each Tree node is true if no more elements can be inserted in it. This saves us from ever needing to backtrack.
The Branch type is used to store the steps which we took to insert the element. This is needed if you're going to implement a fast table lookup (we aren't in this case, so it's just an example.)
Here's the function for adding an element to the tree. You can check the patterns if you like:
> huffTreeAdd :: forall (m :: * -> *) a. > (MonadWriter [[Branch]] m, Num a) => > Tree -> a -> Int -> m Tree > huffTreeAdd tree n ele = huffTreeInner tree n [] > where > huffTreeInner tree n path = > if n == 1 > then case tree of > Empty -> do tell [reverse (TLeft : path)] > return $ Tree False (Full ele) Empty > (Tree False left@(Full _) Empty) -> do tell [reverse (TRight : path)] > return $ Tree True left (Full ele) > else case tree of > Empty -> do left <- huffTreeInner Empty (n - 1) (TLeft : path) > return $ Tree False left Empty > (Tree False left@(Full _) right) -> do > right'@(Tree rightfull _ _) <- huffTreeInner right (n - 1) (TRight : path) > return $ Tree rightfull left right' > (Tree False left@(Tree False _ _) Empty) -> do > left' <- huffTreeInner left (n - 1) (TLeft : path) > return $ Tree False left' Empty > (Tree False left@(Tree True _ _) right) -> do > right'@(Tree rightfull _ _) <- huffTreeInner right (n - 1) (TRight : path) > return $ Tree rightfull left right' > otherwise -> error $ "Didn't match " ++ show tree
Building a tree is then just a case of calling huffTreeAdd for each (depth, element) pair in the Huffman table. We throw away the path of Branches, but this is where you would construct a lookup table if you wanted speed.
> huffBuildTree :: forall a. (Num a) => [(a, Int)] -> Tree > huffBuildTree values = > fst $ runWriter $ foldM (\tree (depth, value) -> huffTreeAdd tree depth value) Empty values >
Looking up values from the tree is very simple, you just walk the tree until you hit an element. This function uses a list of Bools as a list of bits where true means taking the right subtree. It returns the element and the remaining list of bits.
> huffTreeLookup :: Tree -> [Bool] -> (Int, [Bool]) > huffTreeLookup origtree origbits = > huffTreeInner origtree origbits where > huffTreeInner tree bits = > case tree of > Empty -> error $ "Bad Huffman code: " ++ (show origtree) ++ " " ++ (show $ take 15 origbits) ++ " " ++ (show $ length origbits) > (Full x) -> (x, bits) > (Tree _ left right) -> > if head bits > then huffTreeInner right $ tail bits > else huffTreeInner left $ tail bits >
Now that you know the theory, there's just the question of how to read the bytes. Remember that we just need the list of lengths and the list of elements, from that the segment layout is obvious:
| u8 | 0xff |
| u8 | 0xc4 (type of segment) |
| u16 be | length of segment |
| 4-bits | class (0 is DC, 1 is AC, more on this later) |
| 4-bits | table id |
| array of 16 u8 | number of elements for each of 16 depths |
| array of u8 | elements, in order of depth |
Like the quantisation table, the last four rows are repeated for the length of the segment. Here's the parsing function, it returns the class, id and a list of (depth, element) pairs:
> parseDHT :: forall b a. > (Show [b], Num b, Num a, Enum a) => > BS.ByteString -> [(Integer, Integer, [(a, b)])] > parseDHT dht = > parseTable $ BS.drop 2 dht where > parseTable bytes = > if BS.length remainingbytes == 0 > then [(tableclass, ident, reverse values)] > else (tableclass, ident, reverse values) : parseTable remainingbytes > where > Just ([tableclass, ident], rest) = $(bitSyn [PackedBits [4, 4], Rest]) bytes > (lengthsbytes, rest') = BS.splitAt 16 rest > lengths = map fromIntegral $ BS.unpack lengthsbytes > valueslength = sum lengths > (valuesbytes, remainingbytes) = BS.splitAt valueslength rest' > values = snd $ foldl (\(values, acc) (length, number) -> > let (v, newvalues) = splitAt number values > in > (newvalues, (reverse (zip (repeat length) v)) ++ acc)) > ((map fromIntegral $ BS.unpack valuesbytes), []) > (zip [1..16] lengths) >
There are two other segments we need to parse, the start of frame and start of scan. Their exact formats aren't important, they contain what you would expect: the width and height of the image, number of components (axis of colour space) and which tables to use in decoding:
> parseSOF sof = > (fromIntegral height, fromIntegral width, Map.fromList comps') where > Just (_, _, height, width, ncomps, rest) = $(bitSyn [Unsigned 2, Unsigned 1, Unsigned 2, Unsigned 2, Unsigned 1, Rest]) sof > comps = snd $ foldl (\(bytes, acc) _ -> (BS.drop 3 bytes, (fromJust $ $(bitSyn [Unsigned 1, PackedBits [4, 4], Unsigned 1]) bytes) : acc)) (rest, []) [1..ncomps] > comps' = map (\(compid, [hor, ver], qt) -> (fromIntegral compid, (hor, ver, fromIntegral qt))) comps > > parseSOS sos = > (fromIntegral ncomps, fromIntegral dctable, fromIntegral actable, rest) where > Just (headlen, ncomps, _, [dctable, actable]) = $(bitSyn [Unsigned 2, Unsigned 1, Unsigned 1, PackedBits [4, 4], Ignore $ Skip 3]) sos > rest = BS.drop (fromIntegral headlen) sos
There's also a function which translates the return values of these parsing functions into changes in the JpegState structure (which we defined way above if you remember):
> updateJpegState state (segType, bytes) =
> case segType of
> 0xc4 -> foldl addHuffTable state $ parseDHT bytes where
> addHuffTable state (key1, key2, values) =
> state { jsHuffTables = Map.insert key tree (jsHuffTables state) } where
> key = (key1, key2)
> tree = huffBuildTree $ values
> 0xdb -> foldl addQuantTable state $ parseDQT bytes where
> addQuantTable state (id, values) =
> state { jsQuantTable = Map.insert id values (jsQuantTable state) }
> 0xc0 -> state { jsWidth = width, jsHeight = height } where
> (height, width, comps) = parseSOF bytes
> 0xda -> state { jsData = rest, jsDCTable = dctable, jsACTable = actable} where
> (1, dctable, actable, rest) = parseSOS bytes
> otherwise -> state
We're almost ready to start decoding the heart of JPEG - the DCT. When encoding an image, it's split into 8x8 squares of pixels. Each of those squares is then transformed via the DCT (which is fully reversible).
You can think of the DCT as changing the pixels from the time to the frequency domain: the time vs amplitude plot of a waveform is in the time domain and the frequency vs amplitude plot (like you see on a graphic equaliser) is in the frequency domain. The DCT is fully reversible.
You can also think of the DCT as a function which turns an 8x8 pixel grid into a linear combination of the following, graphical basis functions:

There are 64, 8x8 images there. The top left one is called the DC component and all the rest are AC components.
Hopefully you can see that a solid 8x8 block is always some fraction of the top left tile. If the 8x8 block fades towards the bottom, then add in a little of the tile just below. It might not be obvious that all 8x8 pixel blocks can be represented as linear combinations of these tiles, but it's true.
The DC component is the cosine wave which makes no cycles over the 8x8 block. Going one tile left, that's the cosine wave which makes half a cycle over the block. Next tile along makes one cycle over the block and so on. Going left increases the horizontal frequency and going down increases the vertical frequency.
However, the human eye has different sensitivities at these frequencies. Most of the high frequency tiles can be thrown away without any noticeable effect. This "throwing away" is managed by dividing the amplitude of each tile by a fixed number in the hope that many of them go to zero. The bigger the divisor, the lower the quality and the divisors are weighted so that the high frequency components get divided by a larger number.
The list of divisors is the quantisation table which we dealt with before.
You can perform the DCT by correlating the pixel values with the cosine functions, which, for the 1-d case, is the same as multiplying by the DCT matrix:
| 0.3536 | 0.3536 | 0.3536 | 0.3536 | 0.3536 | 0.3536 | 0.3536 | 0.3536 |
| 0.4904 | 0.4157 | 0.2778 | 0.0975 | -0.0975 | -0.2778 | -0.4157 | -0.4904 |
| 0.4619 | 0.1913 | -0.1913 | -0.4619 | -0.4619 | -0.1913 | 0.1913 | 0.4619 |
| 0.4157 | -0.0975 | -0.4904 | -0.2778 | 0.2778 | 0.4904 | 0.0975 | -0.4157 |
| 0.3536 | -0.3536 | -0.3536 | 0.3536 | 0.3536 | -0.3536 | -0.3536 | 0.3536 |
| 0.2778 | -0.4904 | 0.0975 | 0.4157 | -0.4157 | -0.0975 | 0.4904 | -0.2778 |
| 0.1913 | -0.4619 | 0.4619 | -0.1913 | -0.1913 | 0.4619 | -0.4619 | 0.1913 |
| 0.0975 | -0.2778 | 0.4157 | -0.4904 | 0.4904 | -0.4157 | 0.2778 | -0.0975 |
Since each row is orthogonal, the inverse of this matrix is just its transpose.
We represent a matrix as a list of rows, where each row is a list of values. This gives us the transpose, vector*vector, matrix*vector and matrix*matrix functions:
> trans l = if any null l > then [] > else map head l : trans (map tail l) > > vv v1 v2 = sum $ map (uncurry (*)) $ zip v1 v2 > mv mat vec = map (vv vec) mat > mm mat mat2 = trans $ map (mv mat) $ trans mat2
We can also define the inverse 8x8 DCT matrix:
> dctmat n = (take (fromIntegral n) $ repeat $ sqrt (1.0/iN)) : (map row [2..n]) > where > iN = fromIntegral n > row k = map (point k) [1..n] > point k i = (sqrt (2.0/iN)) * (cos ((pi * (2.0 * iI - 1.0) * (iK - 1.0)) / (2.0 * iN))) where > iI = fromIntegral i > iK = fromIntegral k > > idct8 = trans $ dctmat 8
Now we understand that to decode the image we just need to get the DCT coefficients for each 8x8 block, multiply by the quantisation table and perform the inverse DCT to get the pixel values. The remaining question is how to decode the DCT coefficients.
First, the 8x8 blocks are encoded in raster order (left-to-right, top-to-bottom) and, where the image isn't an integer number of 8x8 blocks, the rightmost and bottommost pixels are repeated to make it so.
For each 8x8 block the DC coefficient is encoded first using one Huffman table and the AC coefficients follow (all 63 of them) using another Huffman table (and another coding scheme). Both DC and AC use the same integer encoding scheme however, which is what we'll cover next:
An integer is encoded by Huffman encoding its range and then two's complement encoding the offset within that range. The ranges look like this:
| SSSS (range number) | Range |
|---|---|
| 0 | 0 |
| 1 | -1, 1 |
| 2 | -3..-2, 2..3 |
| 3 | -7..-4, 4..7 |
| 4 | -15..-8, 8..15 |
| 5 | -31..-16, 16..31 |
| ... | ... |
The SSSS value is both the element of the Huffman tree (for DC) and the number of trailing bits. So if you decode 3 from the Huffman tree you take the following three bits from the bitstream. The first of those bits is true if you're counting from the bottom of the positive subrange and false if you're counting from the bottom of the negative subrange. The last two are the number to add onto that base value:
> bitsToInt :: forall a. (Bits a) => [Bool] -> a > bitsToInt bits = > foldl (\acc v -> (acc `shiftL` 1) + (if v then 1 else 0)) 0 bits > > jpegDecodeInt :: Int -> [Bool] -> Int > jpegDecodeInt ssss bits = > value where > classvalue = (1 `shiftL` (ssss - 1)) > positive = head bits > basevalue = if positive > then classvalue > else 1 - classvalue * 2 > extravalue = bitsToInt $ tail bits > value = basevalue + extravalue
The DC value of each DCT block is encoded as the difference from the DC value of the last block decoded. (The DC value of the block before the first one is taken to be 0). This code doesn't do the difference, it just decodes the value:
> huffDCDecode :: Tree -> [Bool] -> (Int, [Bool]) > huffDCDecode tree bits = > (decodedvalue, remainingbits) where > (ssss, rest) = huffTreeLookup tree bits > (decodedvalue, remainingbits) = > if ssss == 0 > then (0, rest) > else (value, rest') where > (ssssbits, rest') = splitAt ssss rest > value = jpegDecodeInt ssss ssssbits
AC values are a little different. Firstly, there's 63 of them in each block and there are usually long runs of zeros between values. Thus the AC Huffman tree decodes two values: an SSSS value (in the lower 4 bits), just like above and an RRRR value (in the upper four bits), which gives the number of preceding zeros.
So if the AC Huffman tree decodes a value of 0x53, that's SSSS = 3 and RRRR = 5 and results in the values [0, 0, 0, 0, 0, x], where x is in the range -31..-16,16..31. You decode the following three bits to find the exact value for x.
There are also special codes for 16 zeros (0x00) and to terminate the AC values for this block (0xf0) since blocks often end with many zero values.
> huffACDecode :: Tree -> [Bool] -> ([Int], [Bool]) > huffACDecode tree bits = > (reverse $ concatMap id result, rest) where > (result, rest) = huffACDecodeInner tree bits [] 63 > huffACDecodeInner tree bits acc 0 = (acc, bits) > huffACDecodeInner tree bits acc n = > let > (rrrrssss, rest) = huffTreeLookup tree bits > (rrrr, ssss) = (rrrrssss `shiftR` 4, rrrrssss .&. 15) > (ssssbits, rest') = splitAt ssss rest > in > if (rrrr == 0 && ssss == 0) > then ((take n $ repeat 0) : acc, rest) > else > if rrrr == 15 && ssss == 0 > then huffACDecodeInner tree rest ((take 16 $ repeat 0) : acc) (n - 16) > else huffACDecodeInner tree rest' ([(jpegDecodeInt ssss ssssbits)] : (take rrrr $ repeat 0) : acc) (n - (rrrr + 1))
Clearly, the Huffman encoding of the AC values works best when there are lots of runs of zeros and lots of zeros at the end. High frequency components are likely to be quantised to zero, but if we take the AC values in raster order the highest frequency components aren't always at the end. Thus the AC values are encoded in zigzag order. Here's a diagram:
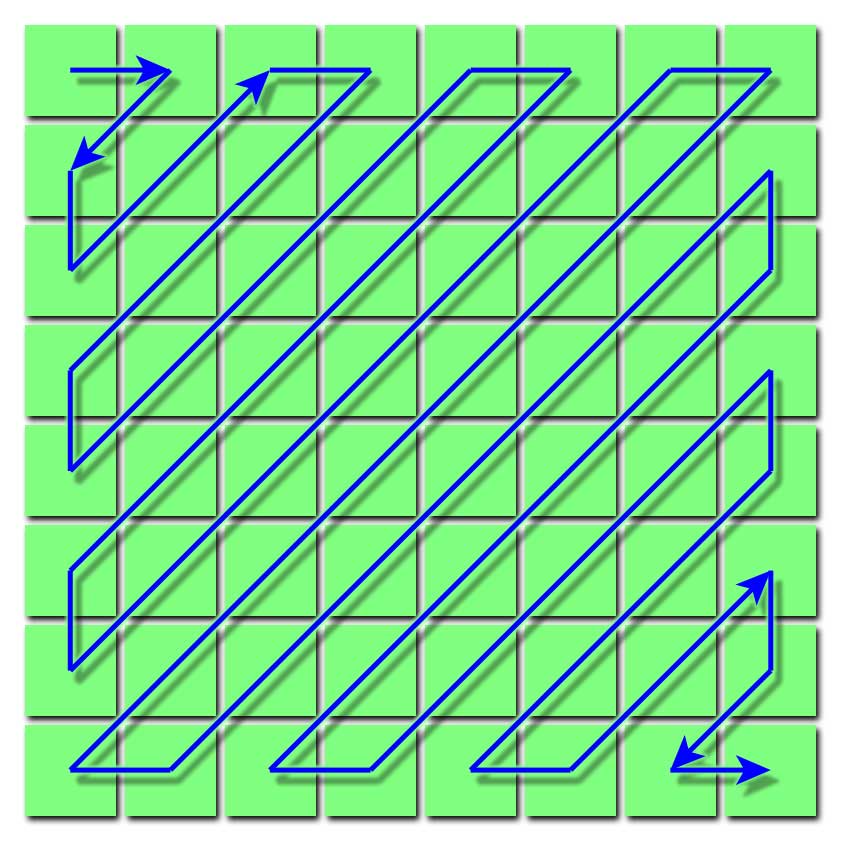
And here's the code:
> deZigZag :: forall a. [a] -> [a] > deZigZag dctvalues = > map ((!!) dctvalues) zigzag where > zigzag = [0, 1, 5, 6, 14, 15, 27, 28, > 2, 4, 7, 13, 16, 26, 29, 42, > 3, 8, 12, 17, 25, 30, 41, 43, > 9, 11, 18, 24, 31, 40, 44, 53, > 10, 19, 23, 32, 39, 45, 52, 54, > 20, 22, 33, 38, 46, 51, 55, 60, > 21, 34, 37, 47, 50, 56, 59, 61, > 35, 36, 48, 49, 57, 58, 62, 63]
We are, at last ready to decode the JPEG, but first I need to get some helper functions out of the way. The first two (groupSize and d8ru) are trivial. The last, bytesToBits converts a block of in memory data into a list of bits, removing the stuffed 0x00 after every 0xff (remember that those stuffed bytes are put there to stop Huffman data looking like the beginning of the next segment).
> -- | Take a list of elements and return a list of lists where each top-level > -- list is l elements long > groupSize :: forall a. Int -> [a] -> [[a]] > groupSize size l = > if length l == 0 > then [] > else take size l : (groupSize size $ drop size l) > -- | Divide by 8, rounding up > d8ru :: Int -> Int > d8ru x = ceiling ((fromIntegral x :: Float) / 8.0) > > bytesToBits :: BS.ByteString -> [Bool] > bytesToBits bytes = > concatMap bitsOf $ removeStuffedBytes $ BS.unpack bytes where > bitsOf b = map (\x -> if x == 0 then False else True) $ map ((.&.) 1) $ map (shiftR b) $ reverse [0..7] > removeStuffedBytes :: [Word8] -> [Word8] > removeStuffedBytes word8s = > removeStuffedBytesInner word8s False where > removeStuffedBytesInner [] False = [] > removeStuffedBytesInner (w:ws) dropThis = > if dropThis > then if w /= 0 > then error "Bad marker in stream" > else removeStuffedBytesInner ws False > else w : (removeStuffedBytesInner ws (w == 0xff))
Now, the decoding function. I've added comments at the end of some of the lines so you can follow along.
First we figure out how many DCT blocks there are (0), this is just the number of blocks in a row times the number of rows over the height of a block. Next, (1) we decode the DC delta and add it to the last DC value (2). Then we can decode all the AC values (3) and multiply all the DCT coefficients by the quantisation table (4).
Finally we de-zigzag and perform the inverse DCT (5) and we're done.
This is done for each DCT block in the file and we end up with a list of 8x8, pixel value matrices. These pixel values run from -128 to 128 (because the DCT works better when they are symmetric about 0). Due to some rounding errors, the actual values may exceed that range and thus they need to be clamped at output time.
> decodeJpeg :: JpegState -> [[[Double]]] > decodeJpeg state = > blocks where > ((dcvalue, rest), blocks) = mapAccumL decodeBlock (0, bits) [1..numblocks] > decodeBlock (pred, bits) _ = > ((dcvalue, rest'), trans $ map (mv idct8) $ trans $ map (mv idct8) (groupSize 8 $ map fromIntegral $ deZigZag dctvalues)) where -- 5 > dctvalues = map (uncurry (*)) $ zip (dcvalue : acvalues) $ map fromIntegral quanttable -- 4 > (dcdelta, rest) = huffDCDecode dctree bits -- 1 > dcvalue = dcdelta + pred -- 2 > (acvalues, rest') = huffACDecode actree rest -- 3 > Just quanttable = Map.lookup 0 $ jsQuantTable state > Just dctree = Map.lookup (0, fromIntegral $ jsDCTable state) $ jsHuffTables state > Just actree = Map.lookup (1, fromIntegral $ jsACTable state) $ jsHuffTables state > bits = bytesToBits $ jsData state > blocksX = d8ru $ jsWidth state > blocksY = d8ru $ jsHeight state > numblocks = blocksX * blocksY -- 0
The last function outputs the list of pixel value matrices to a PGM file. We walk each row of DCT values eight times to get each scanline (0) and, for each pixel value we add 128 and clamp the range (1).
And then there's the main function which just makes an example decoder which reads from test.jpeg and writes to out.pgm.
> writePGM :: forall a. (RealFrac a) => String -> JpegState -> [[[a]]] -> IO ()
> writePGM filename state blocks = do
> h <- openFile filename WriteMode
> hPutStr h ("P5 " ++ (show $ 8 * (d8ru $ jsWidth state)) ++ " " ++ (show $ 8 * (d8ru $ jsHeight state)) ++ " 255\n")
> let outputBlockRow n block =
> BS.hPut h $ toBytes (block !! n)
> toBytes values =
> BS.pack $ map (\x -> fromIntegral $ min 255 $ max 0 ((truncate (x + 128.0)) :: Int)) values -- 1
> outputBlocksInRow blocks =
> sequence_ $ concatMap (\n -> map (outputBlockRow n) blocks) [0..7] -- 0
> outputImage = sequence_ $ map outputBlocksInRow $ groupSize blocksX $ take (blocksX * blocksY) $ cycle blocks
> blocksX = d8ru $ jsWidth state
> blocksY = d8ru $ jsHeight state
> outputImage
> hClose h
>
>
> main = do
> h <- openFile "test.jpeg" ReadMode
> jpegdata <- BS.hGetContents h
> let segments = jpegSegments jpegdata
> state = foldl updateJpegState (JpegState Map.empty Map.empty 0 0 0 0 BS.empty) segments
> writePGM "out.pgm" state $ decodeJpeg state
Here's the result (converted to a PNG):
