TRMNL (27 Jul 2025)
The TRMNL is an 800×600, 1-bit e-ink display connected to a battery and a microcontroller, all housed in a nice but unremarkable plastic case. Because the microcontroller spends the vast majority of the time sleeping, and because e-ink displays don't require power unless they're updating, the battery can last six or more months. It charges over USB-C.
When the microcontroller wakes up, it connects to a Wi-Fi network and communicates with a pre-configured server to fetch an 800×600 image to display, and the duration of the next sleep. You can flash your own firmware on the device, or point the standard firmware at a custom server. The company provides an example server, although you can implement the (HTTP-based) protocol in whatever way you wish.
I considered running my own server, but thought I would give the easy path a try first to see if it would suffice. The default service lets you split the display into several tiles, and there are a number of pre-built and community-built things that can display in each. None of them worked well for me, but that's okay because you can create your own private ones. They get data either by polling a given URL, or by having data posted to a webhook. The layout is rendered using the Liquid templating system, which I had not used before, but it's reasonably straightforward.
I wrote a Go program hosted on Cloud Run which fetches the family shared calendar and converts events from the next week into a JSON format designed to make it trivial to render in the templating system.
With a 3D-printed holder, super glue, and some magnets, it's now happily stuck to the fridge where it displays the current date and the family events for the next week.
The most awkward part of the default service is managing the refreshes. The device has a sleep schedule, and so do the tiles, which are only updated periodically. So the combination can easily leave the wrong day showing. It would be helpful if the service told you when the device would next update, and when a given tile would next update. But it's not a huge deal and, after a little bit of head scratching, I managed to configure things such that the device updates in the early hours of the morning and the tiles are ready for it.
The price has gone up a bit since I ordered one, and you have to pay an extra $20 for the Developer Edition to do interesting things with it. So it ends up a little expensive for something that's neat, but hardly life-changing. But maybe you'll figure out something interesting for it! (Or you can repurpose an old Kindle into a TRMNL device.)
Continuous Glucose Monitoring (29 Jun 2025)
Continuous glucose monitoring has been a thing for a while. It's a probe that sits just inside your body and measures blood glucose levels frequently. Obviously this is most useful for type 1 diabetics, who need to regulate their blood glucose manually.
(At this point, I would be amiss not to give a nod to the book Systems Medicine, which I think most readers would find fascinating. I can't judge whether it's correct or not, but it is a delightful exploration of a bunch of maladies from the perspective of differential equations.)
But CGMs have been both expensive and prescription-only. And I am not a diabetic, type 1 or otherwise. But technology and, more importantly, regulation have apparently marched on, and even in America I can now buy a CGM for $50 that lasts for two weeks, over the counter. So CGM technology is now available to the mildly curious, like me.
The device itself looks like a thick guitar pick, and it comes encased inside a much larger lump of plastic that has a pretty serious-looking spring inside. It takes readings every 5 minutes but only transmits every 15 minutes. You need a phone to receive the data and, if the phone is not nearby, it will buffer some number of samples and catch up when it can. The instructions say to keep the phone nearby at all times, so I didn't test how much it will buffer beyond an hour or so.
I've got both an Android and an iPhone, but for this the iPhone was a more convenient device. So everything following probably applies to both ecosystems, but I've only tested it in one.
The app is well made, although you can feel the lawyers & regulators hovering over every part of it. It gives you instructions about how to “install” the sensor, which you do by holding the big lump of plastic with the spring over a suitable spot on your body and then pressing the button.
It's not a large needle, but it's not trivial either. There is a soupçon of cyberpunk about applying it to yourself in the bathroom but, honestly, my first thought after pressing the button and hearing the bang of the spring releasing was, “oh, it didn't work.” Because I didn't feel anything at all. But when I lifted the applicator away, there it was. And after a little while it started providing readings.
It's held in place with some sticky plastic, and you can shower with it on. After a week or two the plastic does start to get a bit messed up. Honestly, I would have preferred to have replaced cover every few days, but I only got one in the box.
I placed it on the upper arm as suggested in the instructions. I put it a little bit further around and I didn't have any problems laying down on that side.
What did I learn? In a couple of cases, meals that I thought would be fairly healthy (or at least not terrible) were pretty terrible. There'll be some things that I'll avoid eating more than I had before. In the bucket of “things that should have been obvious but the effect is still stronger than I thought”: exercise really works. Even a brisk walk resets my blood sugar quite significantly. And the Hawthorne effect works even when you're doing it to yourself.
The app does not seem to let you export the data. However, at least on iOS you can connect it to Apple Health. And Apple Health does let you export all of your data as a big XML file. So a little bit of Go code later, I have a CSV of everything it recorded and per-day averages and variations.
The sensor will stop working after 15 and a half days. It says exactly 15, but I think it will give you another half day to switch over to another sensor. It comes out easily, although the sticky residue takes some effort to get off the skin.
I did not switch to another sensor. I will probably do it again, but I'll give it a while since, as I expected, most of the insights that I think I'm going to get, I got fairly rapidly. Honestly, I think the gamification of not wanting to spike my blood sugar was perhaps the most effective part of it. I still think it's cool that this is a thing now.
A Tour of WebAuthn (23 Dec 2024)
I've done a bunch of posts about WebAuthn/passkeys over time. This year I decided to flesh them out a bit into a longer work on understanding and using WebAuthn. If you were at the FIDO conference in Carlsbad this year, you may have received a physical, printed booklet of the result. It took a while to get around to converting to HTML, but the text is now available online.
Let's Kerberos (07 Apr 2024)
(I think this is worth pondering, but I don’t mean it too seriously—don’t panic.)
Are the sizes of post-quantum signatures getting you down? Are you despairing of deploying a post-quantum Web PKI? Don’t fret! Symmetric cryptography is post-quantum too!
When you connect to a site, also fetch a record from DNS that contains a handful of “CA” records. Each contains:
- a UUID that identifies a CA
- ECA-key(server-CA-key, AAD=server-hostname)
- A key ID so that the CA can find “CA-key” from the previous field.
“CA-key” is a symmetric key known only to the CA, and “server-CA-key” is a symmetric key known to the server and the CA.
The client finds three of these CA records where the UUID matches a CA that the client trusts. It then sends a message to each CA containing:
- ECA-key’(client-CA-key) — i.e. a key that the client and CA share, encrypted to a key that only the CA knows. We’ll get to how the client has such a value later.
- A key ID for CA-key’.
- Eclient-CA-key(client-server-key) — the client randomly generates a client–server key for each CA.
- The CA record from the server’s DNS.
- The hostname that the client is connecting to.
The CA can decrypt “client-CA-key” and then it can decrypt “server-CA-key” (from the DNS information that the client sent) using an AAD that’s either the client’s specified hostname, or else that hostname with the first label replaced with *, for wildcard records.
The CA replies with Eserver-CA-key(client-server-key), i.e. the client’s chosen key, encrypted to the server. The client can then start a TLS connection with the server, send it the three encrypted client–server keys, and the client and server can authenticate a Kyber key-agreement using the three shared keys concatenated.
Both the client and server need symmetric keys established with each CA for this to work. To do this, they’ll need to establish a public-key authenticated connection to the CA. So these connections will need large post-quantum signatures, but that cost can be amortised over many connections between clients and servers. (And the servers will have to pass standard challenges in order to prove that they can legitimately speak for a given hostname.)
Some points:
- The CAs get to see which servers clients are talking to, like OCSP servers used to. Technical and policy controls will be needed to prevent that information from being misused. E.g. CAs run audited code in at least SEV/TDX.
- You need to compromise at least three CAs in order to achieve anything. While we have Certificate Transparency today, that’s a post-hoc auditing mechanism and a single CA compromise is still a problem in the current WebPKI.
- The CAs can be required to publish a log of server key IDs that they recognise for each hostname. They could choose not to log a record, but three of them need to be evil to compromise anything.
- There’s additional latency from having to contact the CAs. However, one might be able to overlap that with doing the Kyber exchange with the server. Certainly clients could cache and reuse client-server keys for a while.
- CAs can generate new keys every day. Old keys can continue to work for a few days. Servers are renewing shared keys with the CAs daily. (ACME-like automation is very much assumed here.)
- The public-keys that parties use to establish shared keys are very long term, however. Like roots are today.
- Distrusting a CA in this model needn’t be a Whole Big Thing like it is today: Require sites to be set up with at least five trusted CAs so that any CA can be distrusted without impact. I.e. it’s like distrusting a Certificate Transparency log.
- Revocation by CAs is easy and can be immediately effective.
- CAs should be highly available, but the system can handle a CA being unavailable by using other ones. The high-availability part of CA processing is designed to be nearly stateless so should scale very well and be reasonably robust using anycast addresses.
Chrome support for passkeys in iCloud Keychain (18 Oct 2023)
Chrome 118 (which is rolling out to the Stable channel now) contains support for creating and accessing passkeys in iCloud Keychain.
Firstly, I’d like to thank Apple for creating an API for this that browsers can use: it’s a bunch of work, and they didn’t have to. Chrome has long had support for creating WebAuthn credentials on macOS that were protected by the macOS Keychain and stored in the local Chrome profile. If you’ve used WebAuthn in Chrome and it asked you for Touch ID (or your unlock password) then it was this. It has worked great for a long time.
But passkeys are supposed to be durable, and something that’s forever trapped in a local profile on disk is not durable. Also, if you’re a macOS + iOS user then it’s very convenient to have passkeys sync between your different devices, but Google Password Manager doesn’t cover passkeys on those platforms yet. (We’re working on it.)
So having iCloud Keychain support is hopefully useful for a number of people. With Chrome 118 you’ll see an “iCloud Keychain” option appear in Chrome’s WebAuthn UI if you’re running macOS 13.5 or later:

You won’t, at first, see iCloud Keychain credentials appear in autofill. That’s because you need to grant Chrome permission to access the metadata of iCloud Keychain passkeys before it can display them. So the first time you select iCloud Keychain as an option, you’ll see this:
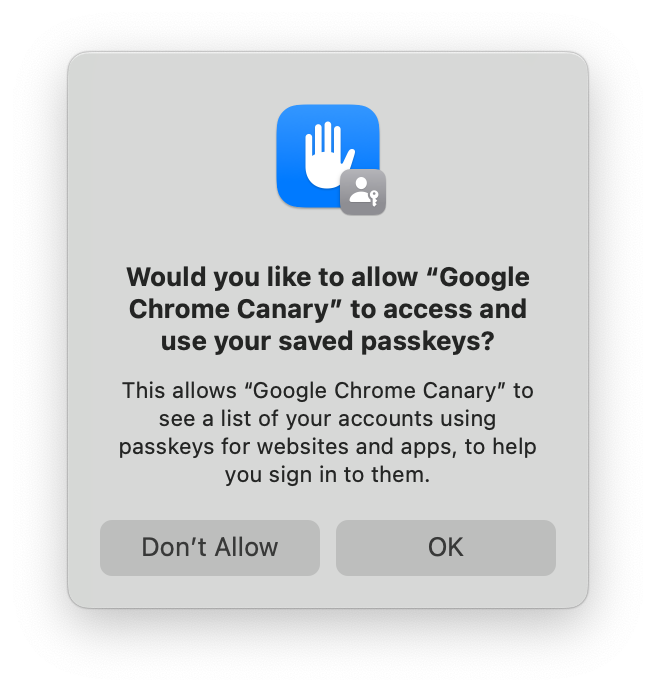
If you accept, then iCloud Keychain credentials will appear in autofill, and in Chrome’s account picker when you click a button to use passkeys. If you decline, then you won’t be asked again. You can still use iCloud Keychain, but you’ll have to go though some extra clicks every time.
You can change your mind in System Settings → Passkeys Access for Web Browsers, or you can run tccutil reset WebBrowserPublicKeyCredential from a terminal to reset that permission system wide. (Restart Chrome after doing either of those things.)
Saving a passkey in iCloud Keychain requires having an iCloud account and having iCloud Keychain sync enabled. If you’re missing either of those, the iCloud Keychain passkey UI will prompt you to enable them to continue. It’s not possible for a regular process on macOS to tell whether iCloud Keychain syncing is enabled, at least not without gross tricks that we’re not going to try. The closest that we can cleanly detect is whether iCloud Drive is enabled. If it is, Chrome will trigger iCloud Keychain for passkey creation by default when a site requests a “platform” credential in the hope that iCloud Keychain sync is also enabled. (Chrome will default to iCloud Keychain for passkey creations on accounts.google.com whatever the status of iCloud Drive, however—there are complexities to also being a password manager.)
If you opt into statistics collection in Chrome, thank you, and we’ll be watching those numbers to see how successful people are being in aggregate with this. If the numbers look reasonable, we may try making iCloud Keychain the default for more groups of users.
If you don’t want creation to default to iCloud Keychain, there’s a control in chrome://password-manager/settings:

I’ve described above how things are a little complex, but the setting is just a boolean. So, if you’ve never changed it, it reflects an approximation of what Chrome is doing. But if you set it, then every case will respect that. The enterprise policy CreatePasskeysInICloudKeychain controls the same setting if you need to control this fleet-wide.
With macOS 14, other password managers are able to provide passkeys into the system on macOS and iOS. This iCloud Keychain integration was written prior to Chromium building with the macOS 14 SDK so, if you happen to install such a password manager on macOS 14, its passkeys will be labeled as “iCloud Keychain” in Chrome until we can do another update. Sorry.